 FEARLUS
FEARLUS
 The James Hutton Institute
The James Hutton Institute
This page is no longer updated. The Macaulay Land Use Research Institute joined forces with SCRI on 1 April 2011 to create The James Hutton Institute.
Floating Point Arithmetic and Agent Based Models
Just like any other kind of modelling technique, agent based models have their problems with floating point arithmetic. From here you can access some of the work we have been doing to investigate the extent of these problems and download the software:
- Charity World: a comparison of various techniques for dealing with the effects of floating point arithmetic in an agent-based model.
- Charity World (Netlogo): a reduced (and unofficial) version of Charity World implemented in Netlogo. This program can be run as an applet.
- The Ghost in the Model: an investigation of the effects of floating point arithmetic in FEARLUS and the Artificial Stock Market.
- Download software utilities developed during the course of this work.
- Support some Requests For Enhancements to Java.
Floating-point arithmetic is the standard way to represent and work with non-integer numbers in a digital computer. It is designed to create the illusion of working with real numbers in a machine that can only strictly work with a finite set of numbers. In many cases, calculations performed with floating-point numbers will produce results which are not significantly different from those obtained using real numbers. However, in many other situations thinking of floating-point numbers as real numbers can be highly misleading. In particular, models with branching statements of the form IF (antecedant) - THEN (consequent), where the antecedant involves a comparison with a floating-point number and the consequent causes some kind of discontinuity, are especially vulnerable. As an example, using the IEEE 7541 standard double precision C datatype double to define the variable ENERGY, the following program results in the undue death of an agent:
ENERGY = 1.2; ENERGY = ENERGY - 0.4; ENERGY = ENERGY - 0.4; ENERGY = ENERGY - 0.4; if (ENERGY < 0) [ AGENT DIES ];
Floating-point errors should not come as a great surprise when one realises that we are squeezing the fully connected infinite set of real numbers into a discrete set of isolated floating-point numbers.

This mapping from real numbers to floating-point numbers is a many(actually infinite)-to-one function which we will denote by []f. Thus, for example, assuming IEEE 754 double precision, [253]f = [253 + 1]f = 253. As a matter of fact, for any real number -0.5 ≤ x ≤ 1, we obtain [253]f = [253 + x]f = 253.
The inexact nature of floating-point numbers creates the following problems:
- Rounding errors in the representation of parameters:
Most real numbers are not exactly representable in floating-point format. In particular, in binary floating-point formats (which most computers use) most of the simple-looking base-10 numbers such as 0.1, 0.2, 0.3, 0.4, 0.6, 0.7, 0.8, and 0.9 are not exactly representable. This means that we will have rounding errors from the very moment we input such numbers in the computer, before we actually perform any operation with them.
- Imprecision in calculations:
The result of an operation, even when the operands are exactly representable floating point numbers, can be an unrepresentable number. We find thus that in any single operation x ⊗ y = z, where x, y and z are real numbers and ⊗ stands for any arithmetic operator, there are two potential sources of error: the first potential source of error lies in the conversion of x and y to their floating point representations [x]f and [y]f. The second potential source of error lies in the conversion of the result of [x]f ⊗ [y]f = z' to its floating point representation [z']f = [[x]f ⊗ [y]f]f.
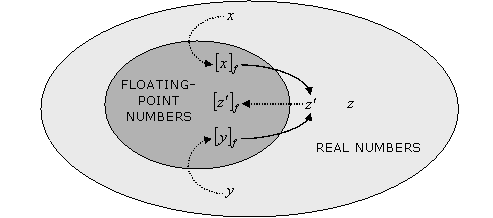
If the result of an operation is used in subsequent calculations, errors can accumulate in our model until they become significant even in the absence of branching statements.
- Loss of basic properties:
Floating-point arithmetic operations lack several properties that we tend to take for granted when implementing our models. Some examples (assuming that floating-point arithmetic complies with the IEEE 754 standard double precision) are the following:
- Floating-point addition does not have the associative law. For example:
(0.1 + 0.2) + 0.3 ≠ 0.1 + (0.2 + 0.3)
- Floating-point multiplication does not have the associative law. For example:
(0.1 × 0.2) × 0.3 ≠ 0.1 × (0.2 × 0.3)
- The distributive law between multiplication and addition does not necessarily hold. For example:
(0.1 + 0.2) × 0.3 ≠ (0.1 × 0.3) + (0.2 × 0.3)
In particular, this loss of basic properties means that expressions such as w = x + y + z are ambiguous when implemented using floating-point arithmetic. For example, consider the calculation 0.1 + (0.2 + 0.3), then using IEEE 754 double precision floating-point standard arithmetic in the following C program:
int main(int argc, char **argv) { double one = 0.1, two = 0.2, three = 0.3, six = 0.6; if((one + (two + three)) != six) { printf("0.1 + (0.2 + 0.3) != 0.6\n"); } else { printf("0.1 + (0.2 + 0.3) = 0.6\n"); } return 0; }This will output
0.1 + (0.2 + 0.3) = 0.6.2However, if we computed the same sum but with the additions in a different order:
int main(int argc, char **argv) { double one = 0.1, two = 0.2, three = 0.3, six = 0.6; if(((one + two) + three) != six) { printf("(0.1 + 0.2) + 0.3 != 0.6\n"); } else { printf("(0.1 + 0.2) + 0.3 = 0.6\n"); } return 0; }From this program we get the output
(0.1 + 0.2) + 0.3 != 0.6If your browser supports Java you can see the output of a similar program in Java in the panel below:
- Floating-point addition does not have the associative law. For example:
Due to the accuracy of floating-point arithmetic, the problems outlined above are not likely to be of major importance if our model does not perform many operations AND if it does not contain branching statements. However if, as in most agent-based models, we find branching statements of the form IF (antecedent) - THEN(consequent), where the antecedent involves a comparison with a floating-point number and the consequent causes some kind of discontinuity, then chances are that our model results are indeed affected by floating-point rounding errors.
[1] IEEE (1985) IEEE Standard for Binary Floating-Point Arithmetic, IEEE 754-1985, New York, NY: Institute of Electrical and Electronics Engineers
[2] N.B. On some Intel machines the output from the C program is 0.1 + (0.2 + 0.3) != 0.6. This is because they do floating-point calculations in 80-bit (double extended) precision by default, rather than 64-bit (double) precision. For more information see (Kahan, 1990) and (Kahan, 1989).